HTML to Word
HTML to Word
The conversion of HTML into Word is one of the most requested functionalities of Javadocx.
There are currently two methods to include HTML into a Word document generated from scratch (the case of templates will be treated further below) with Javadocx:
The first of them uses internally the “alternative content” element available in the OOXML standard (on which Word is based) and it is simple to use although it has two main drawbacks:
- It is not compatible with LibreOffice, OpenOffice and/or PDF conversion
- There is no much flexibility in the rendering options
This said, it may be an interesting option if none of the above represents an issue for a given application.
In what follows we will concentrate in the embedHTML method and the replaceVariableByHTML (its avatar for working with Word templates).
The main advantages of the embedHTML methods are summarised in:
- The HTML code is translated into native WordML code so the resulting document may be rendered in LibreOffice and OpenOffice and transformed to PDF with the help of the Javadocx conversion plugin (included in the Advanced and Premium versions of the library).
- One may use native Word styles for paragraphs and tables.
- One may filter the HTML content to be converted.
- One may include the images included in the HTML code within the Word document or as external resources.
- If there are headings thay may get included into a Table of Contents.
- It allows the direct insertion of HTML+CSS code or the embedding and preprocessing of an external web page.
- The resulting WordML may be also inserted in headers and footers and other targets.
And once again with a single line of Java code.
But let us now get down to the nitty-gritty.
Let us first offer a few simple examples that illustrate the most elementary procedures:
Simple HTML code
The code needed to insert some plain HTML is as simple as this:
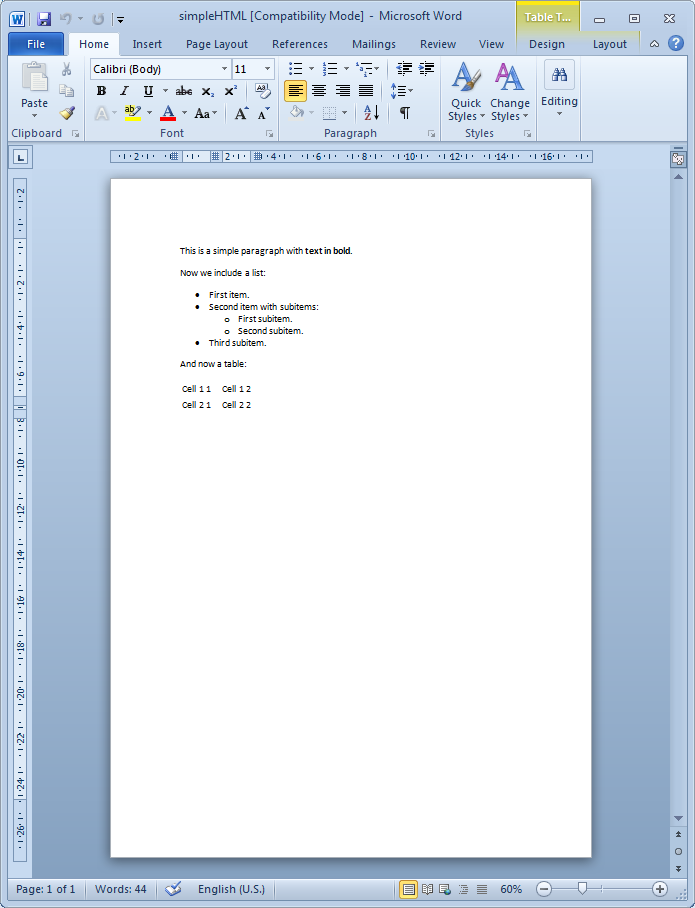
Let us first offer a few simple examples that illustrate the most elementary procedures:
External HTML source
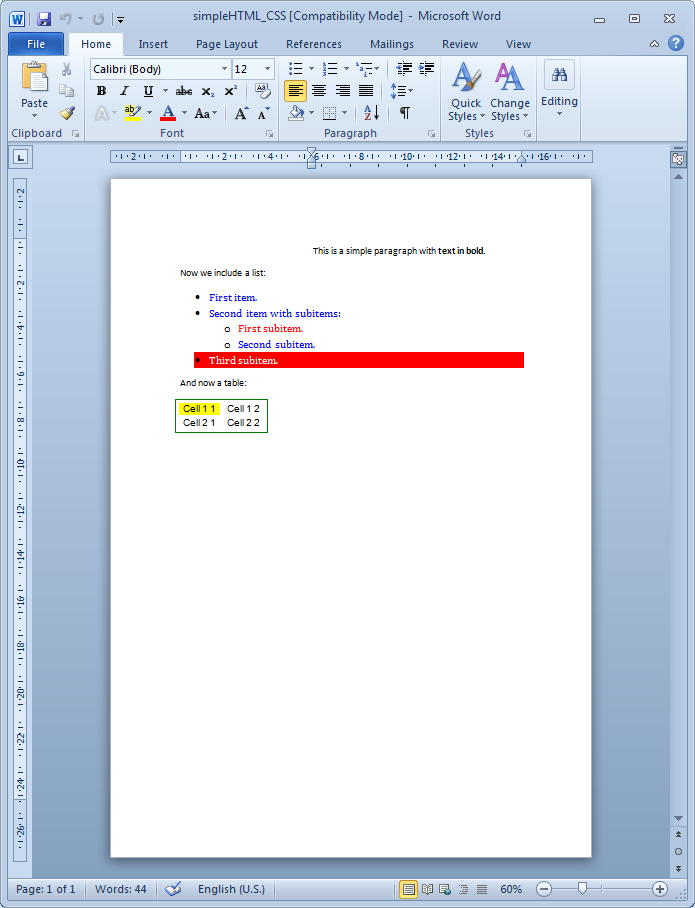
Sometimes one may need to get the HTML and CSS from existing external files but as we will now show this also turns to be extremely simple.
Let us assume that the HTML code above proceeds from an external HTML page: simpleHTML.html that links to a CSS stylesheet: styles.css.
Then the following code will render exactly the same results:
Notice that the only differences are:
- The $html variable is now the path to an external HTML page.
- The option isFile is set to true to indicate Javadocx that the variable $html is a path rather than HTML code.
HTML code embedded within a Word table
It may well be that you choose not to embed directly the HTML code into the document but rather insert it within another document element like a table or a header/footer.
This can be achieved in a very simple way using the WordFragment class.
You may modify slightly the previous example:
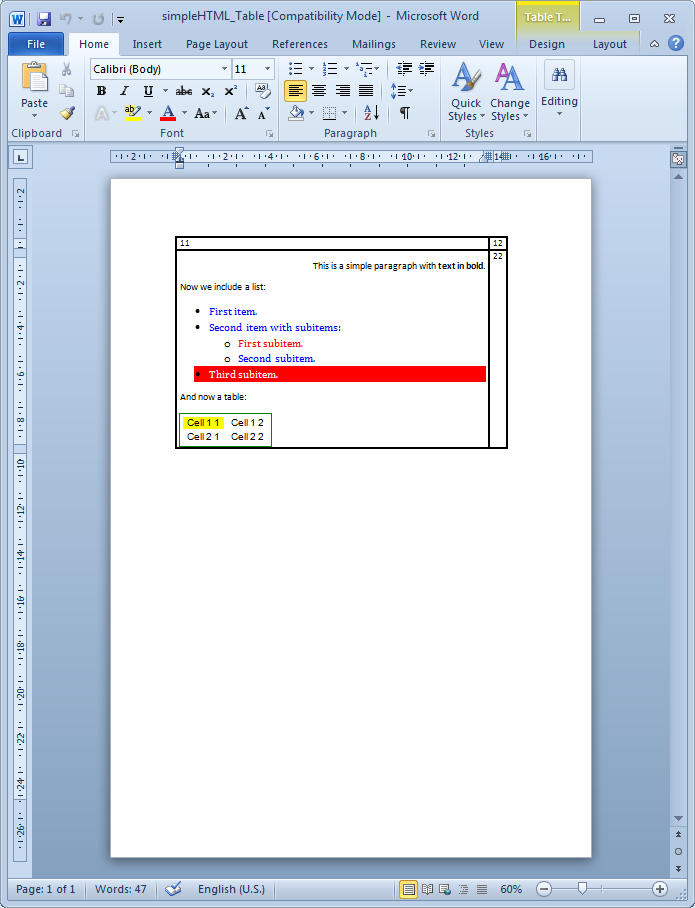
Embedding images
To include images is equally simple. One may choose to include the images within the document (with the option downloadImages set to true) or keep them as an externally linked resource (in that case you should make sure that the image is available to the final users).
A simple example that makes use of this simple web page with an image reads as follows:
Notice that, as in this case you have not declared the width and height attributes of the image, Javadocx reads its properties from the image header and inserts it with a resolution of 96 dpi (default resolution). One may, of course, choose custom width and height to obtain the desired results.
Javadocx parses all the most commonly used HTML tags and attibutes.
It is important to take into account that the HTML and OOXML that Word is based on have different goals so at some points the translation from one to the other should include certain compromises that are not universally valid for all applications. Fortunately it is not difficult to find convenient workarounds that offer a close to perfect Word rendering.
The list of currently parsed HTML elements include:
Block type HTML elements
-
div: Although this tag is probably the most frequent in modern HTML code, it does not have a direct translation into Word. Javadocx offers different parsing options:
- Only use it for the CSS inheritance and parse consequently its child elements.
- Parse them as a "p" element with the option "parseDivs" set to "paragraph" (this may be an useful option when using HTML code coming from a WYSIWYG editor).
- Parse it as a table with the option "parseDivs" set to "table" . This may be the most accurate option if one may decide to preserve all available formatting but may produce complicated Word documents that may be later difficult to edit manually (if that is an interesting option).
- p: This is, of course a native Word element so it is parsed as expected.
- h1, h2, h3, h4, h5 and h6: They are parsed as Word headings and as such they may show up in a TOC included in the Word document.
- ul and ol: Are respectively parsed as unordered or ordered Word lists.
- li: Are parsed like individual list items belonging to a predefined ordered or unordered list.
- dl, dt, dd: Are treated like definition lists in standard HTML.
- table: They are parsed as Word tables and the following attributes are taken into account: border, align and cellspacing. All its children are consequently parsed: thead, tbody, tr, th and td and its corresponding colspan and rowspan attributes.
- img: Images are converted into Word images and they can be integrated in the Word document by setting the option "downloadImages" to true or, if prefered, be kept like an external resource (this option could be particularly interesting if you expect the image to change with time), this requires an open Internet connection whenever the Word document is visualised. Besides the src attribute the width and height are also parsed. All other styling options should be defined via CSS properties. figcaption tag is also supported.
- br and hr: They include, respectively, a line break and an horizontal ruler in the Word document.
Inline type HTML elements
- a: Are parsed as external links, internal links or bookmarks (with the parseAnchors set to true in the last two cases) depending on the value of the href or name attribute.
- strong, b, i, em, u, span, sup, sub, blockquote, address, center, listing, plaintext, xmp, pre, cite, var, dfn, tt, code, kbd, ins, s, strike, del, big, small: Are parsed as text with their corresponding default properties unless they are overwritten by explicit CSS style properties.
HTML web form elements
-
input: Inputs are parsed depending on their type attribute:
- text: Is converted into a Word text field. The size attribute determines the corresponding length in the Word field.
- checkbox and radio: In both cases they are converted into Word checkboxes. The checked is parsed and activates the checked elements in the Word document.
- select and option: They transform into the corresponding Word dropdown field element with their corresponding options. Once again if there is a selected option in the HTML code it appears selected by default in the Word document.
- When a tag is not parsed, it does not mean that its content disappears from the Word document. It only implies that their associated HTML properties are not taken directly into account. Their children and text content will be parsed and rendered with their corresponding styles into the Word document.
WARNING:
Currently almost all CSS properties that are applicable to a document, are parsed and translated into their Word counterparts.
In order to achieve the best possible results it is important to know how these CSS properties are applied and their known limitations regarding the final document rendering.
The list of currently parsed CSS styles include:
Border styles and background color
The following border properties are parsed:
-
border: One may introduce combined properties as, for example, "1px solid red". Some comments about units and format:
- Units: One may use pixels, points or ems.
- Styles: The available styles are: None, dotted, dashed, solid, double, groove, inset, outset.
- Colors: One can enter hexadecimal values like #ff0000 or, if it exists, standard CSS colors like "red" (see standard CSS color names list).
- border-[top, right, bottom, left]: Same as above but letting you choose different borders styles for top, right, bottom and left borders.
- border-[top, right, bottom, left]-color: Sets up independently the color for each border.
- border-[top, right, bottom, left]-style: Sets up independently the style (solid, dotted…) for each border.
- border-[top, right, bottom, left]-width: Sets up independently the size (in pixels, points or ems) for each border.
- border-collapse: Allows to collapse or separate.
- background-color: Hexadecimal or standard CSS value.
Margins and paddings
The concept of padding has not a general direct counterpart in Word so it is usually interpreted as extra margin space.
- margin and padding: One may use pixels, points or ems.
- margin-[top, right, bottom, left] and padding-[top, right, bottom, left]: Same as above but letting you choose different margins and paddings for top, right, bottom and left.
Page break properties
This properties are partially supported:
- page-break-after: If set to avoid is equivalent to the Word property of "Keep with next paragraph".
- page-break-inside: If set to avoid is equivalent to the Word property of "Keep lines together".
- page-break-before: If set to always is equivalent to the Word property of "Break page before". If it is set to avoid turns on Word widow/orphan control.
Font and text properties
The units may be pixels, points or ems and the colors follow the same scheme as above. The suported properties include:
- font: If one uses the shorthand properties one need to preserve the following order: font: font-style font-variant font-weight font-size/line-height font-family.
- font-family: Make sure to include a font family that may be supported by the Word interface (practically all the usual ones). The default value is "serif".
- font-size: The default size is 12pt.
- font-style: May be normal, italic or oblique.
- font-variant: May be normal or small-caps.
- font-weight: Only recognise bold or bolder that are converted into bold in Word.
- line-height: May be set in any of the available units.
- color: Hexadecimal value or standard CSS values.
- text-decoration: May be underline or line-through.
- text-align: The available values are left, center, right or justify.
- text-indent: May be set in any of the available units.
- text-transform: May be set to uppercase.
Positioning
Javadocx tries to adapt as best as possible the positioning properties of elements to equivalent Word properties. If you need to position precisely elements in the resulting Word document the best and simplest way is to do it with tables.
You may also instruct Javadocx to parse divs as tables (see, for example, above) or to parse floats with the "parseFloats" set to true (image floats are always parsed by default).
In any case results are usually pretty good and cover all but the most sophisticated examples.
The parsed properties include:
- float: Can be none, left or right.
- vertical-align: Can be given in pixels, points or ems or like super, sub, top, text-top, middle, baseline, bottom and text-bottom.
Lists
Javadocx handles pretty well the rendering of HTML lists and their associated CSS styles. Nevertheless, if you want to use bullets beyond the most standard ones you should call the Javadocx embedding HTML methods in conjunction with the createListStyle method (by setting the 'customListStyles' option to true) to obtain the desired results.
In order to do so one should create a custom style that mimics the HTML result and give it the same name that is given in the HTML code for the corresponding class or id attribute. Javadocx will automatically choose the corresponding formatting (bullets, indents, etcetera) previously defined.
The following code illustrates how to create a lower letter and roman style list style and use it with HTML:
In any case results are usually pretty good and cover all but the most sophisticated examples.
In case that one does not bother to define any custom list style, the corresponding CSS list style property is parsed as follows:
- list-style and list-style-type: When any of them is set to none no bullets or numbering is included and the CSS properties on margin and padding are used, for all other lists types the standard Word defaults are used.
One of the nicest features of the embedHTML method is that it allows to apply customized Word formatting for paragraphs and tables.
One may write plain HTML with little or none styling and yet generate a very sophisticated Word document.
The default base template already includes all standard Word styles for headings, paragraphs and tables.
Of course, you may choose a different base template that better suits your needs or even explicitely import styles from other DOCX via the Javadocx importStyles method.
Let us now go over a simple example that illustrate this functionality:
Notice that we have set the option strictWordStyles to true so the HTML parser will ignore the CSS properties and will apply exclusively the selected Word styles.
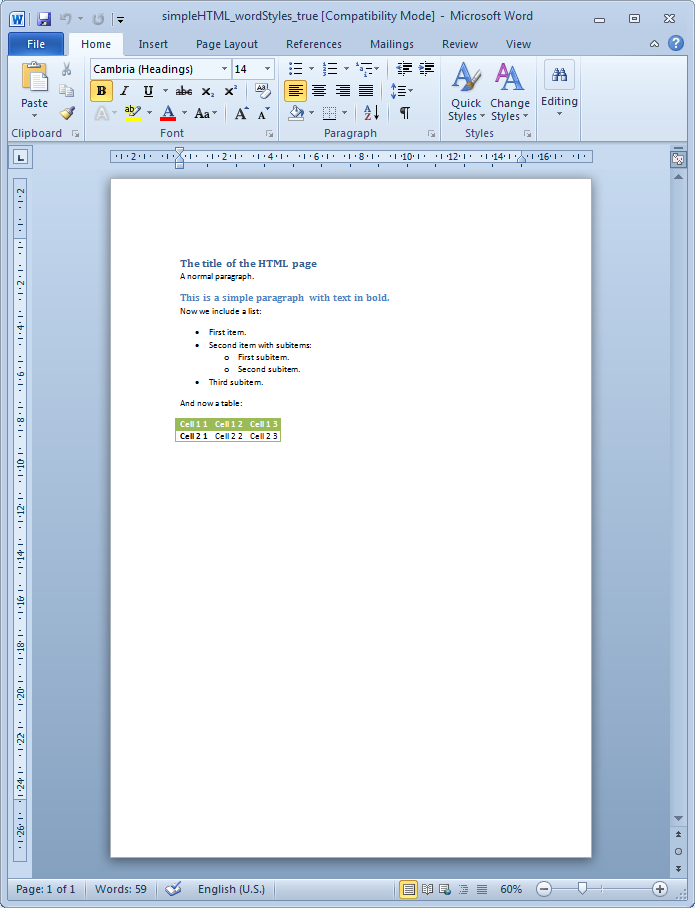
If one removes the option strictWordStyles or set it to false (its default value), Javadocx will try to combine the Word and HTML styles.
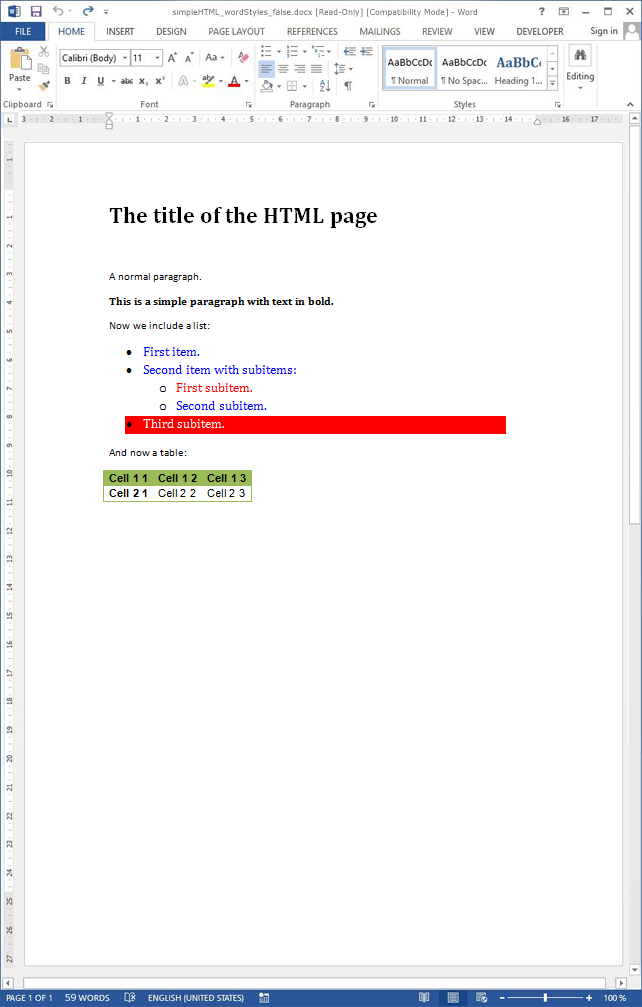
Javadocx adds some default styles when the strictWordStyles option is set as false. The addDefaultStyles option prevents adding these default styles.
Another useful functionality of the embedHTML method is the possibility to filter the HTML content included in the Word document.
One may want to reuse HTML code that has been generated with a different goal in your Word document. A typical example is given by the contents of an existing web page from which you just want to extract its contents without menus or navigation that does not really fit into a Word document.
One can select a set of HTML elements using CSS selectors as follows:
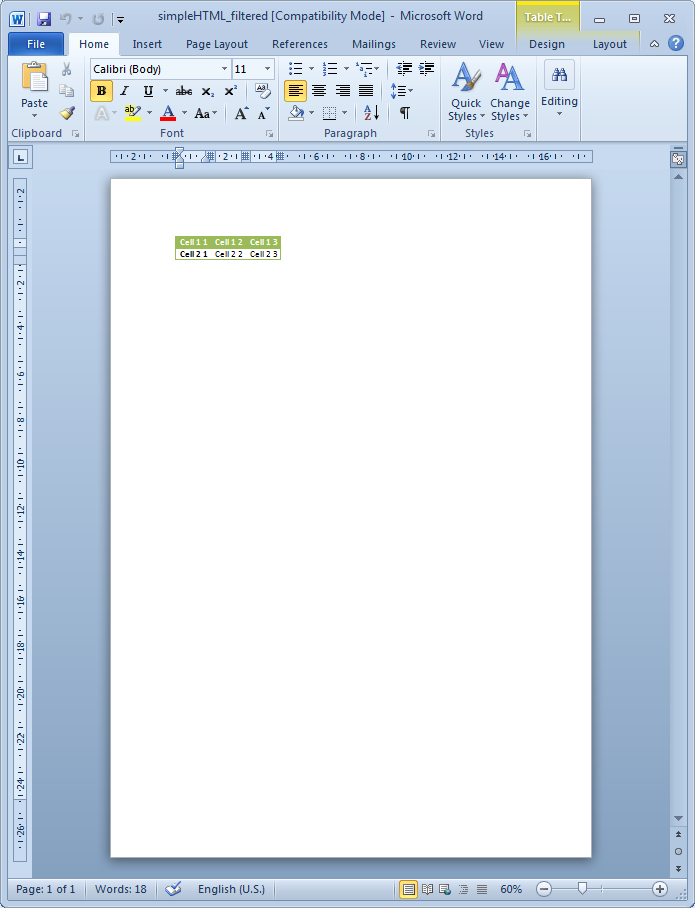
Besides all the options that have been carefully analysed before, there are are other general options that we now pass to comment briefly.
- ‘parseAnchors’ (boolean): If set to true it will parse the anchors included in the HTML file. Its default value is false.
- ‘parseDivs’ (paragraph, table): Although all CSS properties of div tags are inherited divs themselves are not parsed by default because there is no WordML element that exactly resemble its properties. When set to paragraph the Javadocx parser tries to parse them as standard paragraphs (this may be a useful option for HTML coming from certain WYSIWYG editors). If set to table, it renders the div as a Word table. Its default value is false.
- ‘parseFloats’ (boolean): When set to true Javadocx tries to parse the floating divs and paragraphs as floating tables. Sometimes the results are impredictable, so use with care. Its default values is false.
- ‘baseURL’ (boolean): Forces the base URL of the relative links to the desired value. This option may be particularly useful if the HTML code is obtained via the Java file_get_contents method or any similar procedure.
All the preceding examples have their match in the case we are working with templates by means of the replaceVariableByHtml method.
All the available options are the same as before although we have to give two extra pieces of extra info, namely:
- The name of the variable we wish to substitute.
-
The type of substitution that may be:
- block: The whole paragraph containing the variable is replaced by the corresponding HTML.
- inline: Only the variable itself is replaced by the ‘inline’ HTML content (block elements are removed from the code).